Enterprise AI security
How Grail keeps secrets out of agent context
A practical look at how Grail masks passwords, tokens, and other likely secrets before they reach an AI agent in Slack or Teams.
TL;DR: Grail now adds an inbound data loss prevention layer between user messages and the agent. If someone pastes a password, token, or other likely secret into Slack or Teams, Grail masks it before it reaches the model, records why it was masked, and immediately notifies the sender that the value was protected.
This post assumes no security background. The goal is simple: explain what the control does, why it matters, and why we built it in a way that works for both fast-moving teams and enterprise buyers.
The risk enterprises actually care about
AI agents are useful because they sit where work already happens: in Slack, Teams, and the rest of the software stack. That same convenience creates a real security question: what happens when a user pastes something sensitive into the conversation?
In practice, these are rarely dramatic incidents. They are ordinary human moments. A user shares a password for a quick login. Someone pastes an API key while troubleshooting. A token shows up in a long thread because a teammate is moving fast. Enterprises do not just want assurances that “the model is secure.” They want confidence that the product is designed for the messy reality of how people actually work.
That is what this feature is for. It is a practical safety layer that reduces accidental secret exposure without turning every conversation into a compliance workflow.
What happens before the agent sees a message
When a user sends a message to Grail, the system now checks it inside the same Rust service that prepares the request for the agent. We use a balanced ruleset: a combination of explicit regex patterns and lightweight heuristics for things like passwords, bearer tokens, private keys, and credential-bearing URLs.
The flow is straightforward:
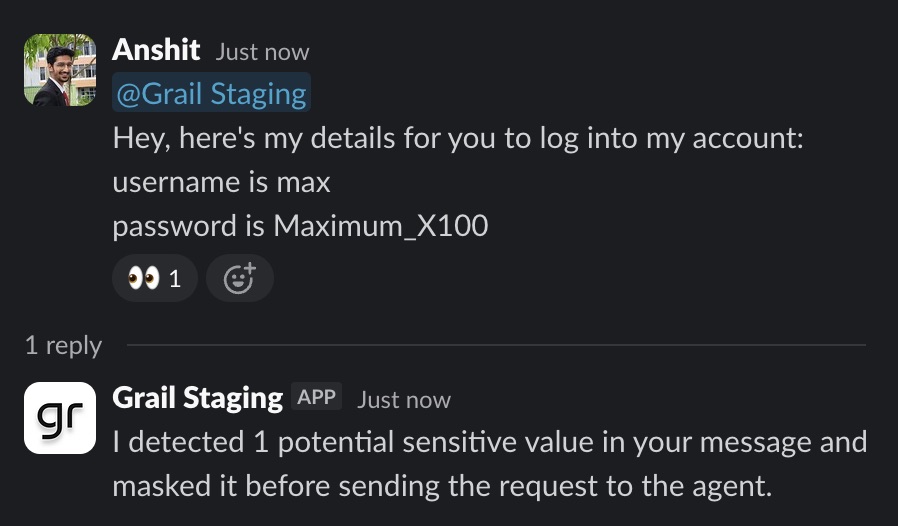
- Grail detects a value that looks sensitive.
- The raw value is replaced with a placeholder such as [masked secret 1].
- The agent receives context about why masking happened, but not the secret itself.
- The user gets an immediate message confirming that Grail masked the value before delivery.
The important design detail: protection has to follow the whole conversation
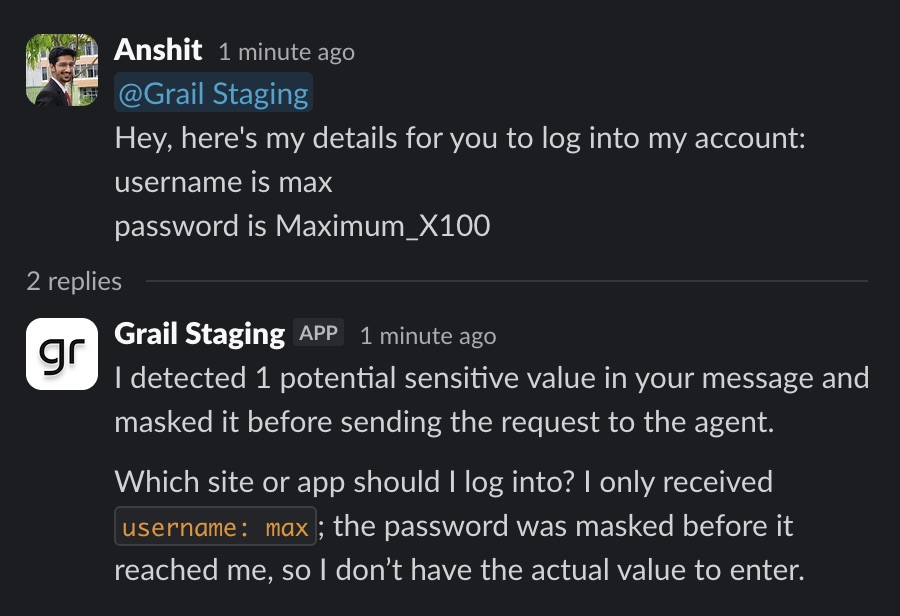
A lot of “we mask secrets” claims fall apart on the second step. It is not enough to inspect only the very first inbound message. In a real deployment, the agent may also receive thread history, prior conversation context, or provider data fetched through tools.
We hardened this feature accordingly. The same masking rules now apply not just at initial message ingress, but also when Grail reconstructs prior Slack or Teams context for the model, and when the Slack and Teams MCP servers return message history or search results. That closes the obvious loophole where a masked secret in the main prompt could still leak through a previous message in the same thread.
Admins control the rules, not just the outcome
Different clients have different tolerances, policies, and naming conventions. Some want very conservative masking. Others want a lighter-touch layer that catches the most common mistakes without over-blocking. We built this so those choices live in the product, not in a hardcoded engineering-only config.
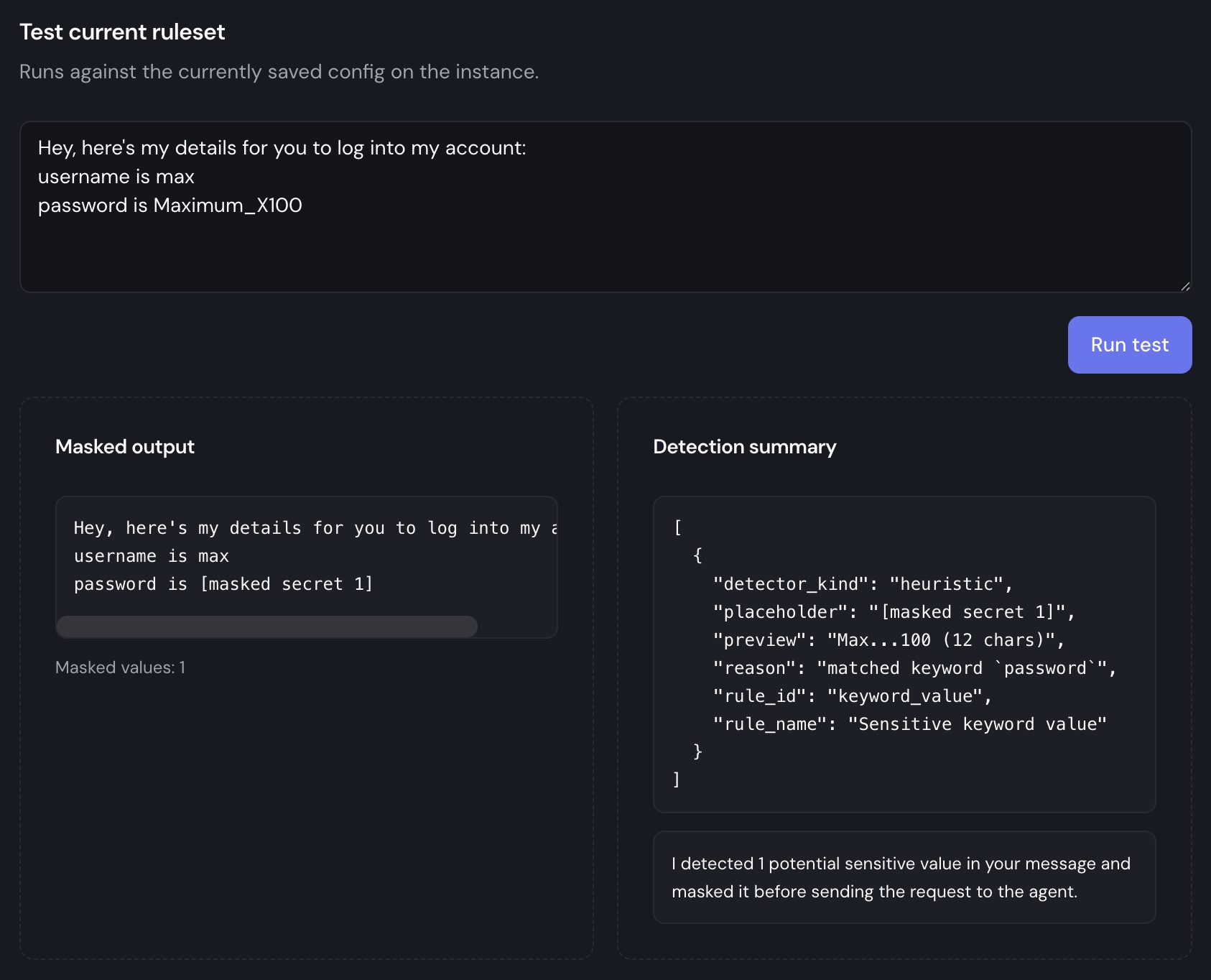
From the dashboard, administrators can:
- Enable or disable the DLP layer entirely.
- Toggle regex and heuristic detection independently.
- Edit rules and priorities without redeploying the agent.
- Test the currently active ruleset against a sample message before rolling changes out.
Why we chose a light, customizable DLP layer
This is intentionally not positioned as a full standalone enterprise DLP suite. For many clients, that would be the wrong product shape. They do not want to wait for a large security program before deploying AI workers. They want a practical control that reduces common risks now, integrates cleanly with approvals and audit trails, and can be tuned over time.
That is why the first version uses regex and heuristics rather than heavy classification. It is easier to reason about, easier to customize, and easier to operate. In security-sensitive environments, explainability matters. An admin should be able to see which rule triggered, why a value was masked, and how to adjust the ruleset if the behavior is too strict or too loose.
What this means for enterprise buyers
If you are evaluating AI agents for a real team, this feature should be understood as part of a broader enterprise posture:
- Safer rollout in chat-based workflows: users can work in Slack and Teams without every accidental paste turning into a model exposure event.
- Defense in depth: masking now covers ingress, thread context, and provider tool reads, not just the obvious front door.
- Operational transparency: admins can inspect, tune, and test the ruleset themselves.
- Human-friendly behavior: users get immediate feedback when something was protected, instead of silent failure or confusing agent behavior.
In short: we are not asking clients to trust vague security language. We are building the product so sensitive data is less likely to reach the agent in the first place.
Trade-offs and boundaries
It is important to be precise about what this does and does not do. A regex-and-heuristics layer is strong against common accidental exposure, but it is not a complete substitute for access controls, approvals, audit logging, model governance, or company-wide security policy. We see it as one useful layer in an enterprise-ready stack, not as a magic answer.
That said, this is exactly the kind of layer that makes AI systems feel deployable in the real world. Enterprise readiness is not just about certifications. It is about handling the predictable operational mistakes that happen once software meets real users.
Security should be visible in the product
We built Grail for teams that want AI workers in production, inside real business workflows, with real governance expectations. This feature reflects that philosophy. Sensitive values should not be one paste away from model context, and admins should not need engineering help every time they want to tighten or test a control.
That is the standard we are aiming for: useful enough for operators, understandable enough for non-technical stakeholders, and credible enough for enterprise buyers doing serious diligence.
Key takeaways
- Grail now masks likely secrets before they reach the model, rather than relying on users to notice mistakes after the fact.
- The protection follows the real conversation path: initial inbound messages, fetched thread context, and Slack or Teams MCP history and search results.
- Admins can customize the ruleset from the dashboard and test it before rolling changes out to a live instance.